
Vibe Training - Auto Train a Small Language Model for Your Use Case


A user finds a weird phrasing. The guardrail misses it. Your customer service bot repeats the same unhelpful answer five times because nobody taught it what “repetition” means in your product. Your healthcare chatbot crosses a line it did not know existed. You patch it with a prompt. It works Tuesday. By Thursday, it does not.
This cycle has a name: duct tape safety. And almost every AI product in production is running on it.
Right now, the default solution is to pass every user interaction through a frontier model with your policy written in the prompt. “Here is our privacy rule, does this message violate it?” GPT models do their best. Sometimes that best is great. But you never fully know which one you are getting, and at scale, inconsistency is a liability. This approach also costs real money. Every user message goes through an expensive model. Every call adds latency. And the uncomfortable truth is that a general-purpose model asked to enforce your specific rules is a brilliant generalist pretending to be a specialist. It can fake it. But it cannot be it.
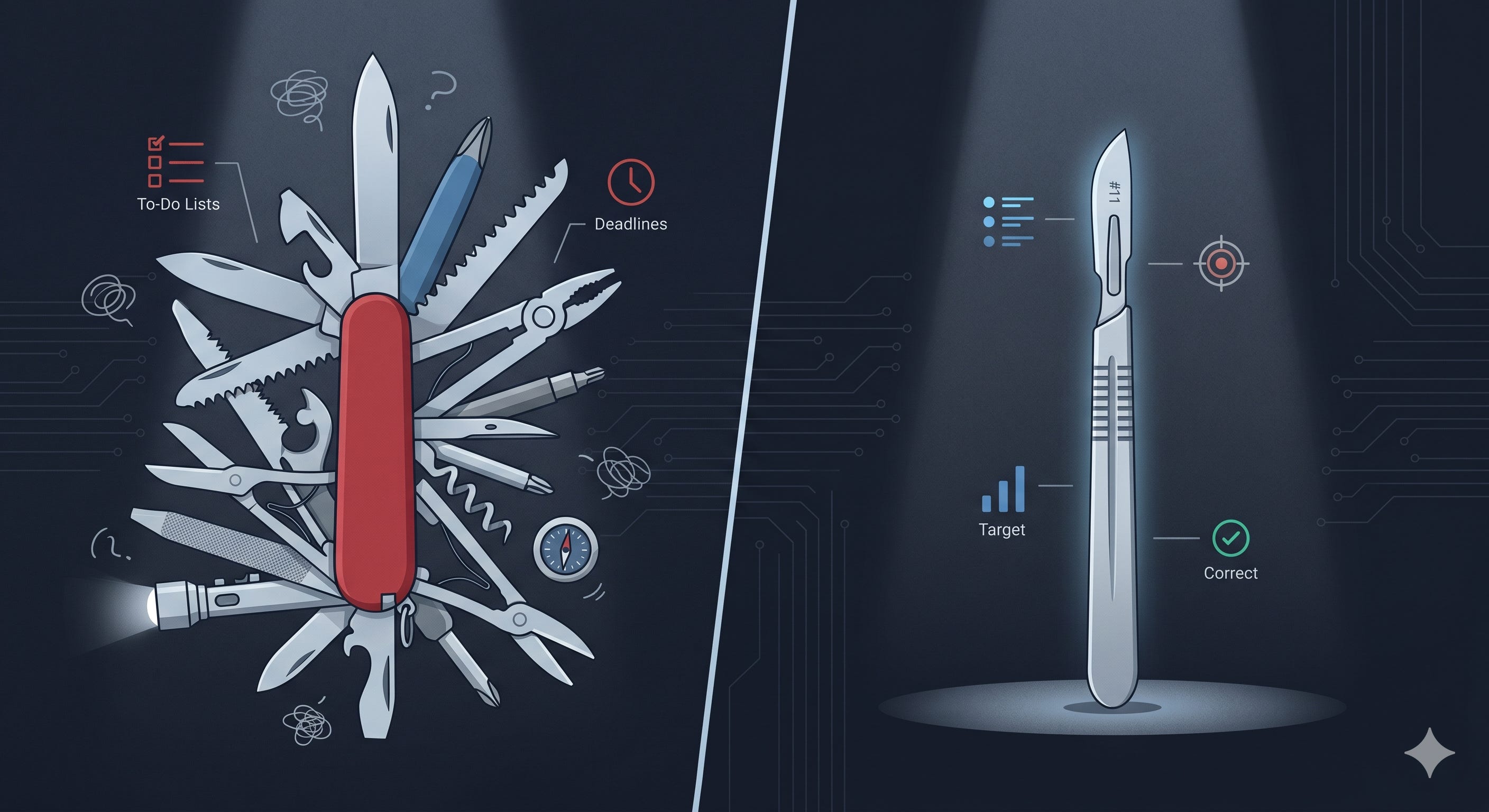
What you actually want is a small, dedicated model that has deeply internalized your exact rule. One that has seen thousands of variations, including the sneaky gray-area cases, and has learned precisely where the line is. Fine-tuned classifiers like this exist and they are dramatically better: smaller in size, lower in inference cost, and far more consistent. The problem has always been getting the training data. Labeled examples cost time and money. Most teams never get there. So they stay on duct tape.
A research team at Plurai just published a framework called BARRED that removes that bottleneck entirely. Give it a description of your policy and a handful of unlabeled examples. It builds the training data itself, verifies every label through structured debate, and hands you a deployable classifier. The results are hard to argue with: a 3-billion parameter model trained with BARRED consistently beat GPT-4.1 and purpose-built safety models with significantly more parameters on custom policy tasks. Here is how it actually works.
The Two Ways Synthetic Data Breaks
The obvious response to the data problem is: just generate it. Ask an LLM to produce thousands of labeled examples of your policy in action. Simple enough, right?
Except it breaks in two specific ways, and both are devastating.
The first is collapse. When you ask a language model to generate examples of a policy violation, it gravitates toward the obvious ones. Imagine asking for “examples of health advice” and getting fifty variations of the same textbook sentence. The examples cluster around the most clear-cut case. But your classifier does not struggle with clear-cut cases. It struggles with the edges, the situations where a reasonable person might pause and think. If your training data never includes those cases, your model becomes confidently wrong exactly where it matters most.
The second is noise. The same model generating your examples is also labeling them. And language models are not perfectly consistent. They rationalize. They hallucinate. An example that should be labeled “violation” sometimes gets labeled “compliant” because the generator happened to focus on the wrong sentence. Train on mislabeled data and your model learns the wrong lessons with complete confidence. The fine-tuning makes it worse, not better.
BARRED was designed specifically to solve both of these, and it does it with two ideas that are independently interesting and together surprisingly powerful.
Step One: Map the Territory Before You Generate Anything
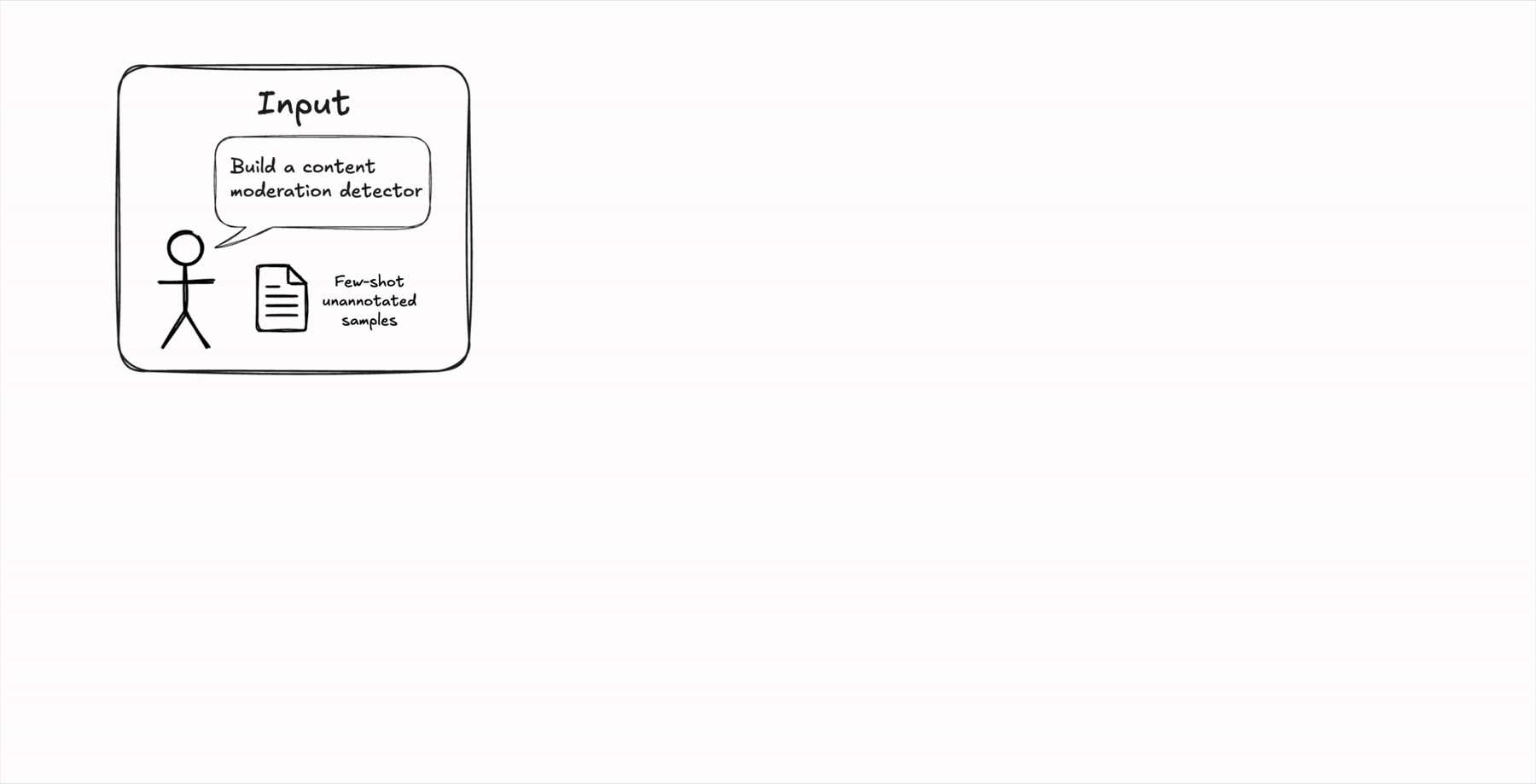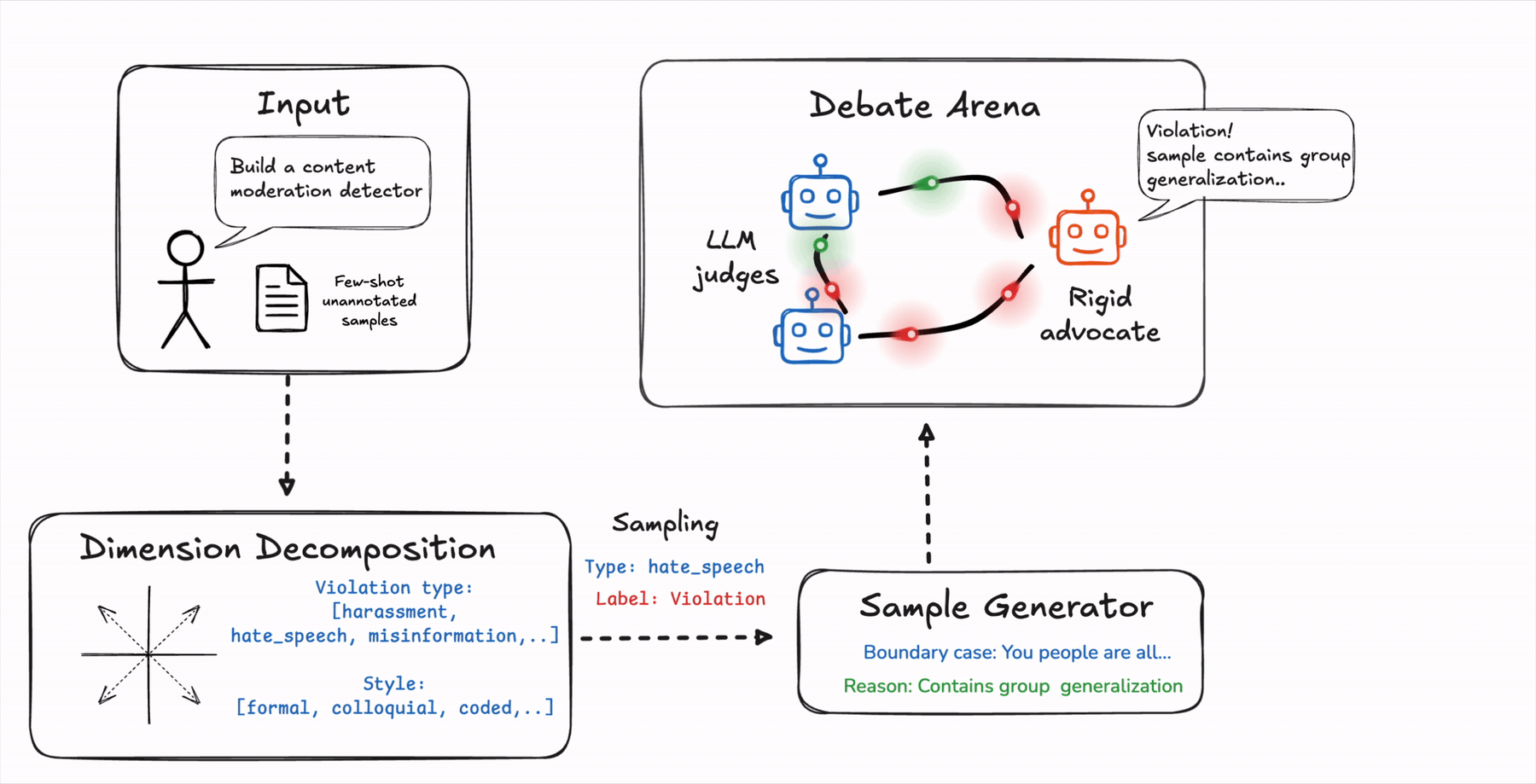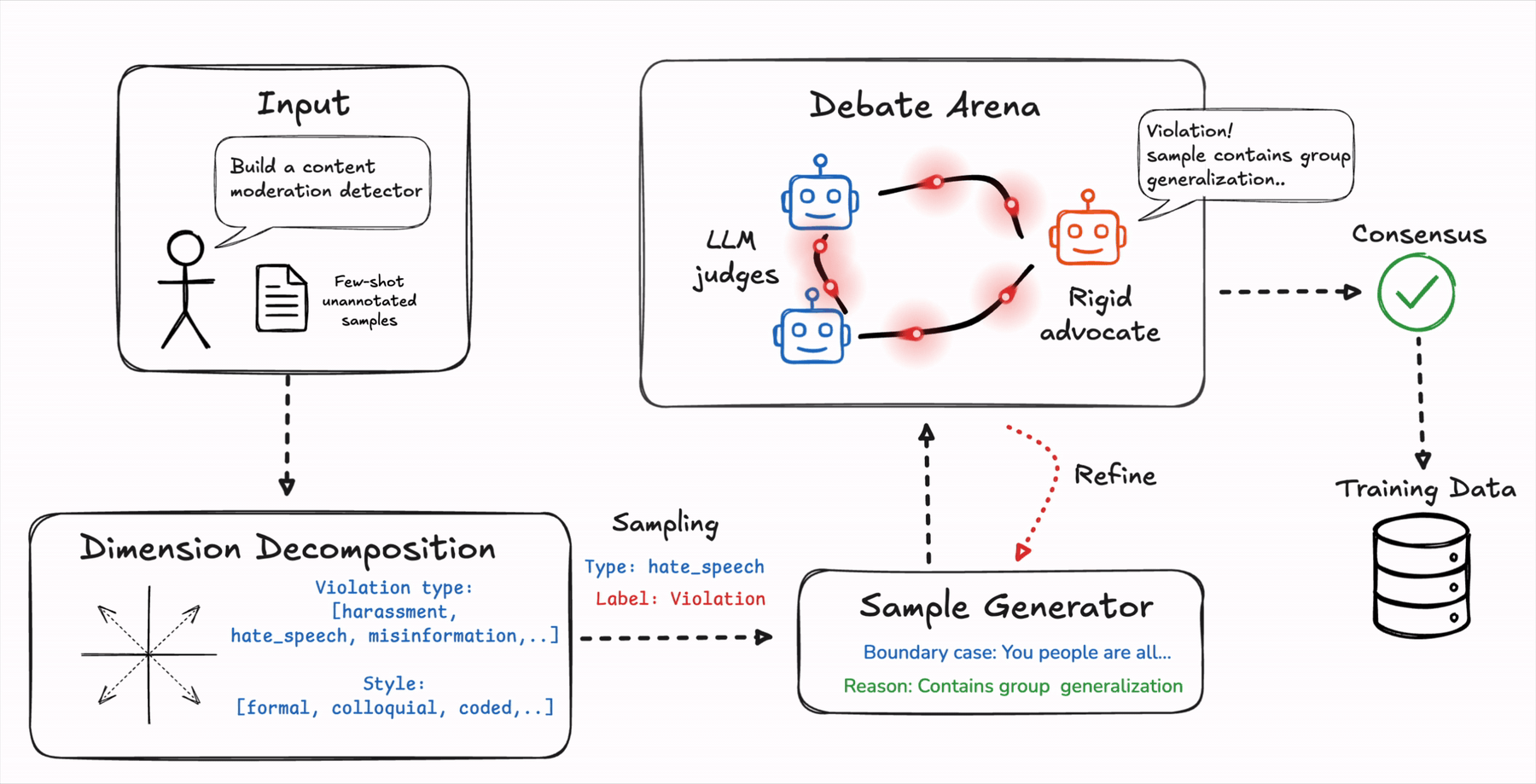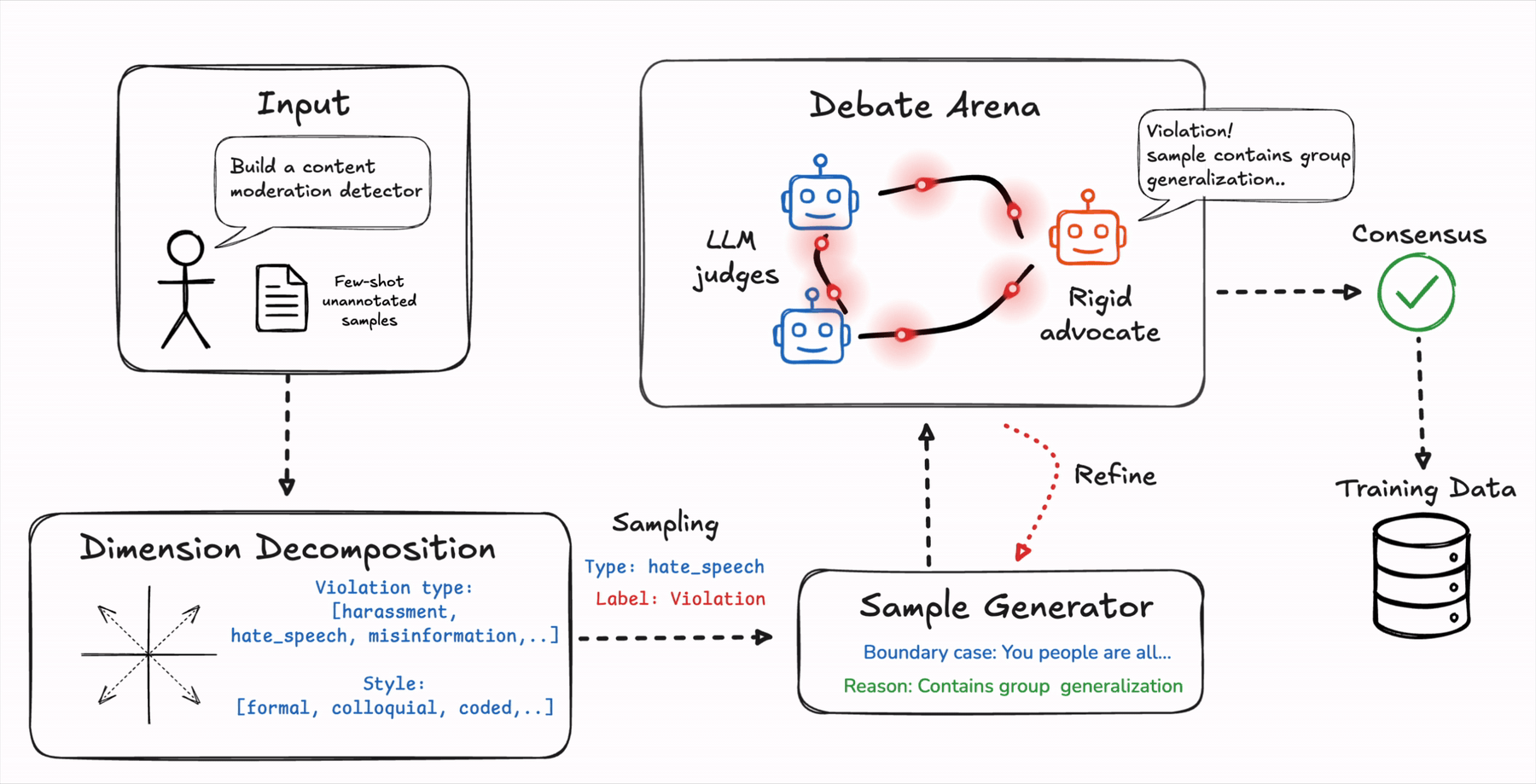
The first thing BARRED does is unusual. Instead of jumping straight to generating examples, it first asks: what are all the dimensions along which this policy can play out?
Take a privacy rule: “never share the GPS coordinates of individual employees.” What are the ways this can unfold in a real conversation? The coordinates could be shared explicitly. They could be implied through a nearby landmark. The question might be about a service location, not a person. The response might reference historical location data. The user might be internal staff with a seemingly legitimate reason to ask.
BARRED identifies these dimensions automatically from your task description and seed examples. It then samples across them systematically, which forces the generated training data to cover the full landscape of your policy, not just the comfortable middle of it. Coverage of the test set increases significantly as more dimensions are added, and model accuracy follows the same curve. Diverse dimensions produce diverse data. Diverse data produces a model that actually generalizes.

This directly solves the collapse problem. Instead of a pile of similar examples all pointing at the same obvious case, you get a training set that looks like the real world, full of variation, context, and nuance.
Step Two: The Courtroom That Verifies Every Label
Solving collapse is only half the problem. You still need the labels to be correct. This is where BARRED does something genuinely clever.
After generating a candidate training example, it does not trust the label the generator assigned. Instead, it runs a structured multi-agent debate. Think of it as a small courtroom that convenes for every single example before it is allowed into the training set.
One agent is the Advocate. It receives the example and the proposed label, and its job is to argue for that label as forcefully as possible. It does not update. It does not doubt itself. It simply builds the strongest possible case for why the label is correct.
A panel of Judge agents then independently evaluates the example and the Advocate’s arguments, deliberating over multiple rounds and updating their assessments as they go. The example is only accepted into the training set when every Judge agrees with the Advocate’s label. Full consensus, or it does not get through.

When the Judges are unconvinced, they explain exactly why in structured feedback. “The text never actually names an individual.” “The location mentioned is a public service address, not a personal one.” That feedback goes back to the generator, which produces a refined version of the example. The refined version enters the courtroom again. The process repeats until the example passes or gets discarded after too many failed attempts.
What makes this design smart is the asymmetry. The Advocate never changes its mind. The Judges do. This means every example has to survive genuine adversarial pressure, not a polite internal review. If the reasoning behind a label cannot convince a skeptical panel, the example probably contains an inconsistency and does not belong in the training data.
The researchers tested what happens when you remove this step. Accuracy dropped 27% when they used raw generated samples with no verification. Even more telling: when they replaced multi-agent debate with single-agent self-review, where the same model that generated the example also critiques it, performance was even worse than no verification at all. Without an opposing voice, the model just confirms what it already believed. It is not review. It is rationalization. Real disagreement is the whole mechanism.
Analysis of over 1,350 debates in the plan verification task alone showed that more than 30% of cases involved non-trivial dynamics: Judges starting in disagreement and converging through argument, or initial consensus breaking down after the Advocate’s reasoning was scrutinized. The debate was not a rubber stamp. It was doing real work.
What Comes Out the Other Side
The fine-tuned models BARRED produces are small and genuinely surprising in how well they perform.
Tested across four distinct domains, customer service dialogue compliance, AI agent plan verification, and healthcare regulatory classification, a 3-billion parameter model trained on BARRED’s synthetic data consistently beat GPT-4.1. It also outperformed dedicated safety models with significantly more parameters across every benchmark.
Simpler rules, like detecting when a user repeats themselves three times, saturate at smaller model sizes. You do not need a big model for a clear-cut rule. Complex rules, like nuanced privacy violations, benefit from more capacity. This means you can size your guardrail to the actual complexity of what it enforces. Nothing wasted.
And on a practical level, the difference between a 3-billion parameter classifier and GPT running on every single user interaction is enormous. In cost. In latency. In what you can actually afford to do at scale. The accuracy win is great. The efficiency win is what makes this real.

You Can Use This Today
The research code is public, but Plurai also went a step further: they built a full UI around BARRED so you do not need to touch any code at all. You describe your policy, upload your examples, and the platform runs the entire pipeline for you. They also ship an MCP server, which means you can plug BARRED directly into your existing AI development workflow and trigger guardrail generation from the tools you are already using.
You can find it at:
The gap between “we handle this with prompts and hope” and “we have a dedicated trained classifier that knows our rules cold” just got much smaller. Not as a research possibility. As a thing you can build today.
The only thing left is the decision to stop patching and start building it right.
Based on BARRED: Synthetic Training of Custom Policy Guardrails via Asymmetric Debate, by Arnon Mazza and Elad Levi, Plurai Inc., accepted at ICML 2026.
a good read , thank you
Very interesting! Does an adversarial agentic system to decide compliance also likely to approve or reject things only becuase of procedural rules that follow the letter of the compliance but break the spirit of compliance?