
SELF-RAG: Revolutionizing AI Language Models with Self-Reflection and Adaptive Retrieval

Hey there, Today we're diving deep into another interesting approach in the world of large language models - Self-Reflective Retrieval-Augmented Generation (SELF-RAG). If you've been following the latest trends in AI, you know that Retrieval-Augmented Generation (RAG) is all the rage. But what if I told you there's a way to make your RAG pipeline even more powerful? Enter SELF-RAG!
The Problem: Balancing Knowledge and Flexibility
Large language models (LLMs) like GPT-4, Claude, Gemini, etc have shown remarkable abilities in generating human-like text and understanding context. However, they often struggle with two key issues:
Factual Inaccuracies: LLMs can sometimes produce incorrect information. This happens because they rely solely on the knowledge encoded in their parameters during training.
Lack of Up-to-date Information: Once an LLM is trained, it can't access new information without being retrained. This means that as the world changes and new information becomes available, these models quickly become outdated. They can't incorporate new facts or events that occurred after their training cutoff date.
Previous attempts to solve these issues led to the development of Retrieval-Augmented Generation (RAG). RAG systems automatically retrieve relevant information from an external knowledge base to supplement the model's knowledge. However, this approach has its own set of challenges:
Information Overload: RAG systems often retrieve information for every query, even when it's not necessary. This can lead to information overload, where the model has to process large amounts of potentially irrelevant data.
Irrelevant Data Incorporation: Not all retrieved information is relevant or useful. Traditional RAG systems might incorporate irrelevant data into their outputs, potentially reducing the quality and accuracy of the generated text.
Lack of Discretion: These systems don't have a built-in mechanism to decide when retrieval is actually needed, potentially wasting computational resources on simple queries that don't require external information.
Enter SELF-RAG: A Smarter Approach
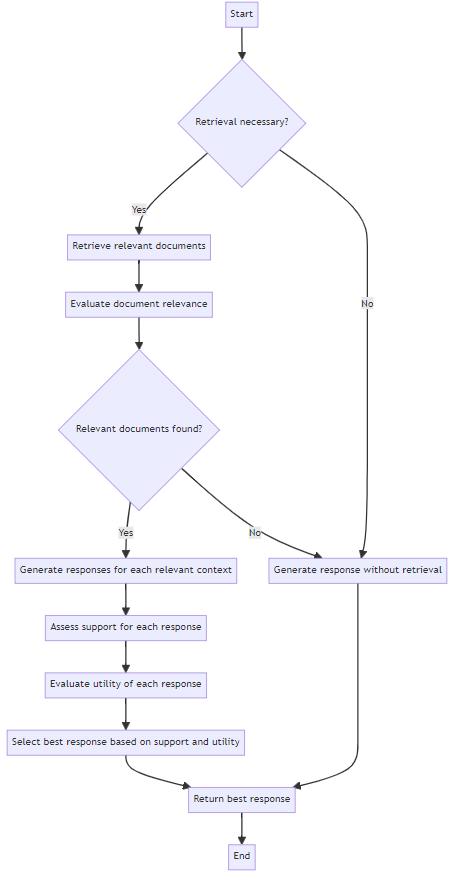
SELF-RAG takes a novel approach to these challenges. Instead of blindly retrieving information for every query, it teaches the language model to decide when retrieval is necessary and how to critically evaluate the retrieved information. Let's break down how SELF-RAG works:
1. Self-Reflection through Reflection Tokens
At the heart of SELF-RAG are special tokens called "reflection tokens." These are added to the language model's vocabulary and serve as a mechanism for the model to pause and think about its own process. Here are the key types of reflection tokens:
Retrieve: This token indicates whether the model needs to fetch external information. The model generates this token based on its assessment of whether the current query can be answered with its existing knowledge or if it needs additional data.
ISREL (Is Relevant): After retrieving information, the model uses this token to assess how relevant the retrieved data is to the current task. This helps filter out irrelevant information that might not contribute to answering the query.
ISSUP (Is Supported): This token is used to evaluate how well the model's generated text is supported by the retrieved information. It acts as a fact-checking mechanism, ensuring that the model's output aligns with the external data.
ISUSE (Is Useful): The model uses this token to rate the overall utility of its generated response. This serves as a final quality check, ensuring that the output is not just accurate but also helpful and relevant to the user's query.
By generating these tokens as part of its output, SELF-RAG makes its thinking process transparent and controllable. This allows for fine-tuning of the model's behavior and provides insights into how it arrives at its conclusions.
2. On-Demand Retrieval
Unlike traditional RAG methods that retrieve information for every query, SELF-RAG only does so when the model deems it necessary. Here's how this process works:
The model first attempts to answer the query using its inherent knowledge.
If it determines that external information is needed (indicated by the Retrieve token), it triggers the retrieval process.
The retrieval system fetches relevant documents or data from an external knowledge base.
The model then incorporates this retrieved information into its reasoning process.
This adaptive approach preserves the model's ability to handle a wide range of tasks efficiently. For simple queries or creative tasks that don't require factual information, the model can rely on its own knowledge, saving computational resources.
3. Critical Evaluation of Retrieved Information
SELF-RAG doesn't just blindly incorporate retrieved data. It has a built-in evaluation process:
After retrieval, the model uses the ISREL token to assess the relevance of each piece of retrieved information.
It then uses the ISSUP token to determine how well this information supports the generation it's about to make.
Based on these assessments, the model decides how to incorporate the retrieved data into its response.
This critical evaluation ensures that only helpful and accurate data influences the final output, reducing the risk of incorporating irrelevant or misleading information.
4. Flexible Inference
One of the most powerful aspects of SELF-RAG is its ability to adjust its behavior at inference time without retraining. This is achieved through the use of the reflection tokens:
Users can adjust the weights assigned to different reflection tokens. For example, increasing the weight of the ISSUP token would prioritize outputs that are strongly supported by evidence.
These adjustments can be made on-the-fly, allowing for task-specific optimization without the need for retraining the entire model.
This flexibility enables the model to adapt to different types of queries or different user preferences for precision vs. creativity.
The Training Process: Teaching Self-Reflection
Training a SELF-RAG model involves several innovative steps:
Critic Model Training:
A separate "critic" model is initially trained to generate reflection tokens.
This critic is trained on a dataset where each example includes an input, an output, and the appropriate reflection tokens.
The training data for the critic is created using a combination of human annotations and outputs from advanced language models.
Data Augmentation:
The training data for the main SELF-RAG model is augmented with reflection tokens.
For each training example, the critic model is used to generate appropriate reflection tokens.
This augmented dataset teaches the main model to generate both content and self-reflective assessments.
End-to-End Learning:
The final SELF-RAG model is trained on this augmented dataset.
It learns to generate content, decide when to retrieve information, and critically evaluate both the retrieved information and its own output.
The model is trained using a standard language modeling objective, but with the added task of predicting the correct reflection tokens.
Fine-tuning and Optimization:
After initial training, the model can be fine-tuned for specific tasks or domains.
The weights for different reflection tokens can be adjusted during this phase to optimize for particular performance characteristics (e.g., factual accuracy vs. creative expression).
Why SELF-RAG Matters
The implications of SELF-RAG are far-reaching:
Improved Accuracy: By intelligently incorporating external knowledge and critically evaluating its own outputs, SELF-RAG models show significant improvements in factual accuracy across various tasks.
Enhanced Versatility: The model retains its ability to handle a wide range of tasks, from creative writing to factual question-answering. It can seamlessly switch between relying on its inherent knowledge and retrieving external information as needed.
Transparency and Verifiability: The reflection tokens provide insight into the model's decision-making process. This makes it easier to verify and trust its outputs, as users can see when and why the model decided to retrieve information or how confident it is in its responses.
Customizability: The ability to adjust the model's behavior at inference time opens up new possibilities for task-specific optimization. Users can fine-tune the model's performance without retraining, adapting it to different use cases or preferences.
Efficiency: By retrieving information only when necessary, SELF-RAG can be more computationally efficient than models that always retrieve data. This can lead to faster response times and lower operational costs.
Continuous Learning: While SELF-RAG doesn't continuously learn in the traditional sense, its ability to retrieve up-to-date information allows it to incorporate new knowledge into its responses without full retraining.
Results and Future Implications
In experimental evaluations, SELF-RAG has shown impressive results:
It outperformed state-of-the-art LLMs and traditional RAG models on a diverse set of tasks, including open-domain question answering, reasoning, and long-form generation.
Notably, it showed significant improvements in factual accuracy and citation precision for long-form text generation.
The model demonstrated an ability to adapt its retrieval and generation strategies based on the complexity and nature of the query.
As AI continues to integrate more deeply into our daily lives, approaches like SELF-RAG that enhance accuracy, transparency, and flexibility will be crucial. This method paves the way for:
More reliable AI assistants that can explain their reasoning and sources.
Accurate information retrieval systems that can handle complex, multi-faceted queries.
AI systems that can potentially explain their own reasoning processes, enhancing interpretability.
Adaptive models that can tailor their behavior to different users or contexts without needing to be retrained.
Conclusion
SELF-RAG marks a significant advancement in large language models, enabling them to reflect on their knowledge, seek information when needed, and critically evaluate their outputs. This brings us closer to AI systems that reason more like humans. As SELF-RAG evolves, we can anticipate more accurate and adaptable AI models across various domains. This innovation exemplifies how creative approaches can solve persistent AI challenges, opening up exciting possibilities for self-reflective AI systems in numerous industries.
If you found this article informative and valuable, and you want more:
Join our Community Discord
Connect with me on LinkedIn
Follow on X (Twitter)
🤗 And of course:
#SELF-RAG #AI #MachineLearning #InformationRetrieval #NLP