
Fine-Tuning AI Models: How They Evolve from General Knowledge to Specialized Experts
From Pre-Trained Foundations to Expert AI: How Fine-Tuning Shapes Smarter, Specialized Models

The morning sun pours through the windows of a busy restaurant kitchen. A master chef works with practiced precision, their knife gliding across the cutting board as they prepare ingredients for the day's service. After years of mastering French cuisine, they've decided to expand their expertise to include Japanese dishes. Rather than starting from scratch, they're building on their foundational skills – their understanding of heat, timing, and flavor combinations – while picking up new techniques unique to Japanese cooking. Every cut and cook shows to their ability to adapt and grow, showing how mastery evolves through continuous learning.
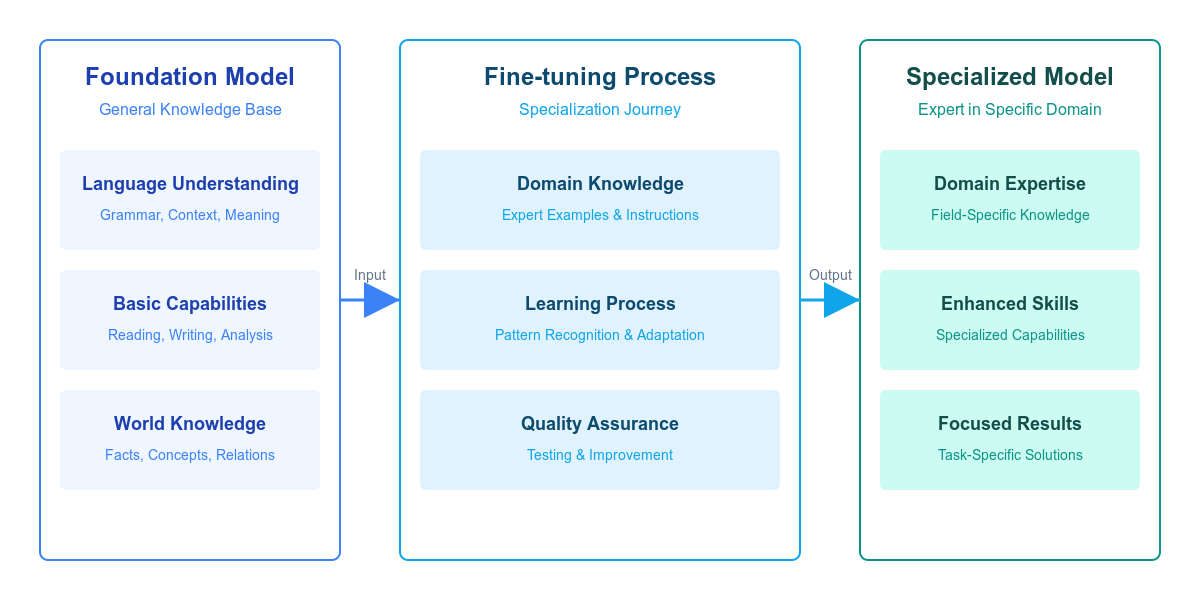
This journey is a fitting analogy for one of the most interesting concepts in AI: fine-tuning Large Language Models (LLMs). Just like the chef doesn’t need to forget everything they know about cooking to master a new cuisine, an LLM doesn’t start from scratch to specialize in a domain. Instead, it builds on its existing knowledge and adapts it to meet specific needs, creating a specialized tool that shines in a focused area. Fine-tuning helps AI become more precise and tailored to unique challenges, much like our chef adapting their skills to a new cooking style.
Link to my GitHub repo that contains a code tutorial on Fine-Tuning: Repo Link
The Foundation: Understanding Pre-Trained Models
Before diving into fine-tuning, it’s important to understand the starting point. Imagine a huge library where every book, article, and conversation ever written has been distilled into patterns of understanding. That’s essentially what happens during the pre-training phase of an LLM. The model learns how language flows – how words fit together, how ideas connect, and how knowledge weaves across topics. It’s like building a mental map of language, connecting concepts and meanings across a vast range of subjects.
During pre-training, the model gains a wide understanding. It knows that "cat" and "feline" mean the same thing, that "Excel" is a tool for organizing data, and that "lungs" help us breathe air into our bodies. This knowledge connects together, just like a chef’s knowledge of heat works whether they are grilling meat or melting chocolate. The model builds a flexible starting point, ready to answer general questions and handle many kinds of requests.
Pre-training creates a robust foundation, but it’s akin to a chef who’s read countless cookbooks without specializing. They have wide-ranging knowledge but lack the instincts that come from hands-on, focused practice. They understand techniques but may not yet excel in a specific type of cuisine. For specialized tasks, such general knowledge must be fine-tuned and tailored to meet unique needs.
The Need for Specialization
Now, imagine walking into a medical clinic and being greeted by a doctor who uses casual, imprecise language, mixing medical terms with slang. While they might get their point across, their communication wouldn’t inspire much confidence. Similarly, a pre-trained LLM, while impressive, may lack the precision and understanding needed in specialized fields. Without refinement, its responses may seem too broad or lack the detail required to meet domain-specific standards.
This is where fine-tuning comes into play. For example, a healthcare organization might need an AI assistant to handle patient inquiries. While the base model understands medical terms and conversational flow, it might miss critical nuances. Consider this interaction:
Patient: "What were my test results from last week?" Base Model: "Your test results showed elevated levels. You should probably check with your doctor about that."
This response, while comprehensible, falls short. It doesn’t address privacy regulations, verify the user’s identity, or follow proper healthcare protocols. It lacks the professionalism and compliance expected in such a scenario, highlighting the need for targeted refinement. Fine-tuning ensures that the AI assistant not only communicates effectively but also adheres to the specific rules and expectations of its field.
The Art and Science of Fine-Tuning
Fine-tuning isn’t about forcing new information into the model. It’s about guiding it to apply its existing knowledge in specific ways. Think of it as training our French chef to master the precise temperature control for sushi rice or the perfect angle to slice fish for sashimi. The chef already knows heat and knife skills – they’re just refining them for a new context, ensuring their skills match the demands of the new cuisine.
Similarly, fine-tuning an LLM for healthcare involves training it to:
Use formal, clear language for medical communication
Apply its knowledge of privacy and security specifically to healthcare regulations
Turn complex medical concepts into patient-friendly explanations
This process begins with carefully chosen examples that illustrate the desired behavior. For instance:
Patient: "What were my test results from last week?" Desired Response: "I understand you’re asking about test results. For your security and privacy, I can only discuss medical information after verifying your identity through our secure patient portal. Would you like me to guide you through the verification process?"
This example teaches the model several key lessons:
How to identify requests for protected health information
The correct protocol for handling such requests
The proper tone and terminology for medical communication
How to guide users toward secure solutions
Each lesson builds on the model’s existing understanding, helping it adapt to the specific demands of its new role. By working through a variety of tailored examples, the model gradually becomes more adept at handling specialized tasks with confidence and accuracy. Fine-tuning transforms the general capabilities of the model into expert-level skills tailored to unique needs.
The Delicate Art of Fine-Tuning
Fine-tuning is a balancing act between preserving general capabilities and fostering specialized expertise. Adjusting the model’s internal weights and connections is like tweaking a chef’s knife grip for sashimi cutting – the basic motion stays the same, but the precision improves. This process requires a careful blend of technical adjustments and data-driven decisions.
Several factors are crucial to this process:
Learning Rate: This controls how quickly the model adapts to new information. Set it too high, and the model risks overwriting its general knowledge. Set it too low, and it might not adapt enough. Finding the right balance is key, ensuring the model learns efficiently without losing its versatility.
Layer Selection: LLMs are built in layers, each handling different aspects of language understanding. Fine-tuning might involve adjusting all layers, focusing on specific ones, or even adding new layers. It’s like deciding whether our chef needs to revisit basic knife skills or just add specialized techniques. The approach depends on the task’s complexity and the depth of specialization required.
Fine-tuning requires careful calibration to avoid overfitting. Striking this balance ensures the model remains both specialized and adaptable, capable of handling a variety of tasks within its domain. Additionally, ongoing testing during the process ensures that fine-tuning enhances the model without compromising its broader abilities.
The Challenge of Data Curation
Creating the right training data is one of the biggest hurdles in fine-tuning. It’s not just about gathering examples – it’s about designing a curriculum that shows the model what to do and how to think. The quality and variety of this data directly impact the success of the fine-tuning process.
For instance, a high-quality healthcare dataset might include:
Different ways patients might ask about test results
Various types of medical information requests
Scenarios where privacy and urgency overlap
Examples of explaining medical concepts clearly
Situations involving patients with varying levels of medical knowledge
Solution: Overcoming this challenge involves:
Diverse Data Sources: Gather examples from multiple scenarios to cover a wide range of language styles and topics.
Expert Annotations: Use domain experts to ensure data is accurately labeled and contextually relevant. Labeling the data means adding tags or categories to explain what each example is about. For instance, in a medical dataset, a question like 'Can you help me book an appointment?' might be labeled as 'appointment-related,' while 'What do my test results mean?' might be labeled as 'test-results-related.' These labels help the model understand the purpose and context of the data, making it easier to learn how to respond correctly. During training, the model uses these labels to identify patterns and relationships, learning how to classify and respond appropriately based on the labeled examples.
Continuous Improvement: Regularly analyze model errors and add examples to address weak spots, ensuring the model continues to learn.
Synthetic Data: Create examples for rare but important cases, enhancing the model’s ability to handle edge cases effectively. For instance, if the AI is trained for customer support, synthetic data might include unique or unlikely scenarios, such as a user asking for help during a system outage. This ensures the model can respond appropriately even when faced with unusual situations.
By following these strategies, we ensure the model learns not just specific answers but how to approach problems thoughtfully and reliably. Thoughtful data curation ensures that fine-tuning produces robust, reliable, and effective models.
The Hidden Complexities
Fine-tuning presents challenges like overfitting, where the model becomes so specialized it struggles with general tasks. Imagine a chef so focused on sushi that they forget how to make basic sauces. This imbalance can reduce the model’s overall utility.
Solution:
Regularization: Techniques like dropout prevent the model from relying too heavily on specific patterns, encouraging broader adaptability. Regularization is a method used during training to ensure the model doesn’t overfit, or become too specialized to the training data. It works by adding constraints or adjustments that encourage the model to generalize better, helping it perform well on new, unseen tasks. For example, dropout randomly ignores parts of the model during training, forcing it to rely on a wider range of patterns rather than just memorizing specific ones.
Selective Fine-Tuning: Adjust only the layers most relevant to the task, preserving general capabilities.
Cross-Validation: Test the model on diverse data to ensure it performs well beyond the training set, maintaining a balance between specialization and generalization.
Multi-Task Learning: Train the model on multiple tasks to encourage flexibility and reduce the risk of tunnel vision.
Another challenge is maintaining ethical boundaries. A model fine-tuned for medical advice must balance specialized knowledge with adherence to strict ethical guidelines.
Solution:
Ethical Constraints: Build explicit rules into training to guide the model’s behavior.
Output Audits: Regularly review the model’s responses to ensure compliance with ethical standards.
Human Oversight: Involve human reviewers for sensitive or high-stakes cases to maintain accountability.
Adversarial Testing: Simulate challenging scenarios to test the model’s responses and ensure safety and reliability.
By addressing these complexities head-on, we can create fine-tuned models that are both effective and responsible, capable of delivering specialized results without compromising broader applicability. Ensuring ethical and practical reliability is a key part of successful AI fine-tuning.
Modern Approaches and Innovations
Techniques like Parameter-Efficient Fine-Tuning (PEFT) and Low-Rank Adaptation (LoRA) are transforming fine-tuning. PEFT selectively trains parts of the model, reducing computational needs without sacrificing effectiveness. LoRA, on the other hand, introduces small, trainable matrices that tweak specific layers, making the process more efficient for large models.
These methods make fine-tuning accessible to organizations with limited resources, much like teaching a chef streamlined techniques to master new cuisines without losing their core skills. They highlight the growing efficiency of modern AI training methods, opening doors for broader applications. By making fine-tuning faster and more affordable, these innovations enable AI to reach a wider range of users and industries.
The Future of Specialized AI
Looking ahead, fine-tuned LLMs will play a pivotal role. We’re moving toward a future where AI assistants aren’t just generally capable but deeply specialized for specific fields. This transformation has the potential to revolutionize industries and redefine how we interact with technology.
Imagine AI assistants that:
Communicate in your organization’s exact style and terminology
Navigate regulatory requirements seamlessly, ensuring compliance
Deliver expert-level support in niche domains with accuracy
Handle thousands of interactions consistently while adapting to individual needs
The potential for customization and scalability is enormous, paving the way for smarter, more efficient workflows across sectors. Fine-tuning allows AI to move beyond general usefulness to become essential tools tailored to specific challenges.
The Art of Balance
Fine-tuning is all about balance: between specialization and versatility, between efficiency and effectiveness. It’s not about restricting a model but enhancing its abilities. As we refine these techniques, we’re not just creating smarter AI – we’re building systems that bridge general intelligence with specialized expertise, unlocking new possibilities for tailored, impactful applications. The key is to ensure that these systems grow responsibly and effectively, setting the stage for the next wave of AI innovation.